掌握以下几点,画出C站一模一样的Stable Diffusion图片
学习Stable Diffusion的时候,看到别人发现的很精美的图片,总也想自己画出来。明明拿着作者公开的绘画参数,却始终画不出和原作者图片一样的效果。
这主要因为影响Stable Diffusion出图的设置的选项巨多,除了参数,还有非常多的选项会影响到出图结果。
比如以下展示的demo,图一为原作者发的图,图二为使用本地Stable Diffusion画一张一模一样的。

图一
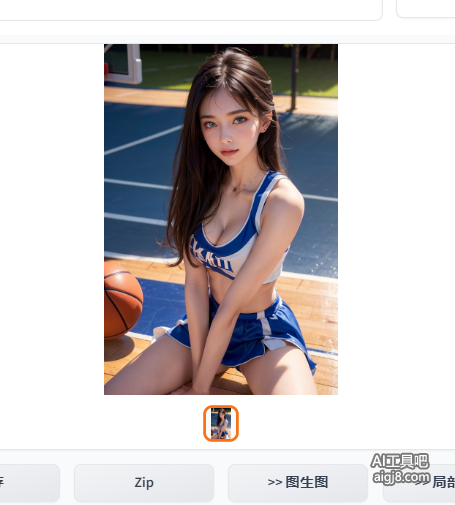
为了画出和作者发布的一模一样的图片,小编进行了以下步骤,经过几次修改后,才实现了出图一样。
1、获取作者公开的基本的绘画参数,对于没有公开绘画参数的图片,直接放弃好了。
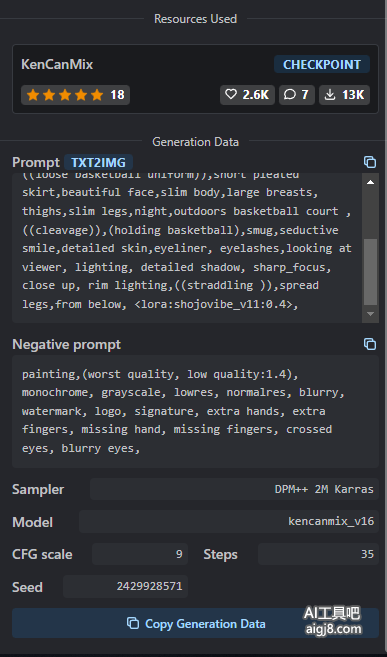
庆幸的是,以上绘画参数,没有太多需要安装部署的东西,比如pt文件,特写vae文件。
但参数中明显看到使用了lora模型 shojovibe_v11,所以必须找到这个模型并下载部署到本机Stable Diffusion。
同时把基础模型也下载部署到本机。
2、设置一样的采样器,迭代步数,提示词相关度,随机种子
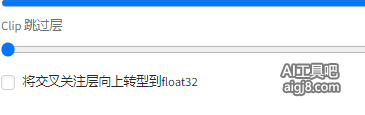
3、参数中没有显示跳过层,表示默认是1,需要确认本地Clip
4、设置里模型的 VAE (SD VAE),一般影响色彩 这些,不至于和原图差距太大,可尝试vae-ft-mse-840000-ema-pruned.ckpt和Anything-V3.0.vae.pt
5、最重要的一点,尺寸,尺寸只要有一点点不一样,出的图片就可能完全不一样了。
打开作者原图,查看尺寸比如,他们一般是768*512 512*768 640*960 等类似这种类型的2倍高清放大,你只需要得到他的尺寸除2就行。
本文由stable diffusion在线绘画 aigj8.com 分享,转载请注明出处。
本文网址:https://www.aigj8.com/stablediffusion/311.html
